Computational tools for low-resource languages
A major component of my research interests is the application of modern computational tools for linguistic analysis to new domains of inquiry. This manifested itself in a recent research project, in which I investigated the viability of various stochastic and computational modeling techniques to aid in the documentation and description of low-resource languages, including finite-state representations of morphology and various approaches to supervised and unsupervised morphological segmentation of unsegmented text.
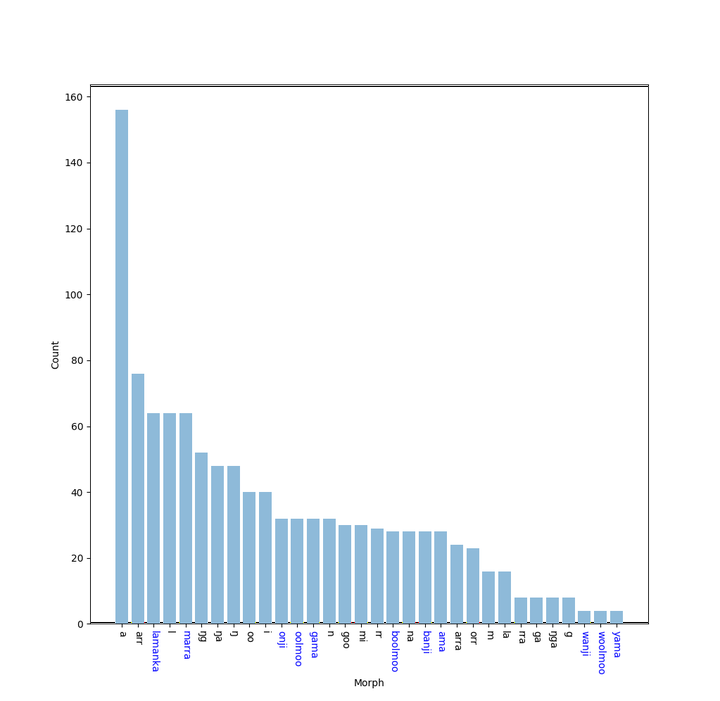
The stated goal of this research was to provide a tool for theoretical or field linguists who may only have access to limited amounts of data. Unlabeled inflectional paradigm data provides a challenge for automatic segmentation models, as the adjacence of specific stems and affixes often results in morphologically-conditioned phonological variation, meaning that the model will not see strong evidence for the existence of a low frequency phonological stem or affix variant. This is an issue not encountered in more traditional applications of these models to the task of segmenting words in a sentence or paragraph, as wordforms generally do not change their orthographic shape based on surrounding context.
In order to demonstrate the viability of automatic segmentation models for aiding in small-scale linguistic analysis, I constructed a small dataset consisting of 320 inflected verb forms representing the full paradigms of five ambivalent verbs (can be both transitive or intransitive depending on context) in Bardi, an Indigenous language of Australia. The proposed computational model was employed in segmenting the Bardi dataset in supervised and unsupervised scenarios. For the supervised model, I also examined the utility of different approaches to creating hand-labeled training data, representing the initial effort of the linguist to hand-segment some of the inflected forms before automating the rest of the process. The findings of this work indicated that the potential for the application of modern computational tools in assisting with morphological analysis for low-resource languages is promising, as appreciable segmentation results were obtained from authentic, attested small-scale language data.
Of primary interest in extending this work is enhancing the representation of linguistic forms in the model to include information about the morphosyntactic properties they encode.
Parker Brody
PhD Candidate
Yale University Department of Linguistics. Computational linguistics, Historical linguistics, Morphological Theory.